Zacznijmy od utworzenia plików tekstowych na potrzeby naszego poradnika, jeden będzie zawierał dane wejściowe, drugi zaś będzie plikiem docelowym przyjmującym dane.

Po utworzeniu obu plików i zasileniu jednego z nich wartościami przejdźmy do pierwszego kroku, w tym celu wybieramy Data Flow Task z lewego menu narzędzi (SSIS ToolBox) i przerzucamy go na główne okno Control Flow.
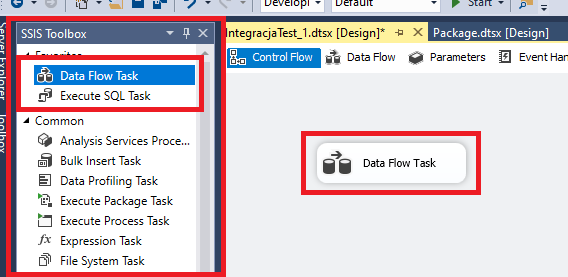
Dwukrotne kliknięcie w nowo utworzone zadanie przeniesie nas do szczegółów konfiguracji i tym samym do kolejnej zakładki jaką jest Data Flow. tutaj możemy wybierać z szerokiej gamy narzędzi służących do pobierania danych, transformacji czy załadowania ich do miejsca docelowego.
Dla pierwszego kroku wykonamy proste zadanie wykonywane pomiędzy plikami. Wybierzmy zatem z dostępnych narzędzi „Flat File Source”, pozwala ono na pobieranie danych ze wskazanego przez nas pliku źródłowego. Przejdźmy do konfiguracji połączenia:
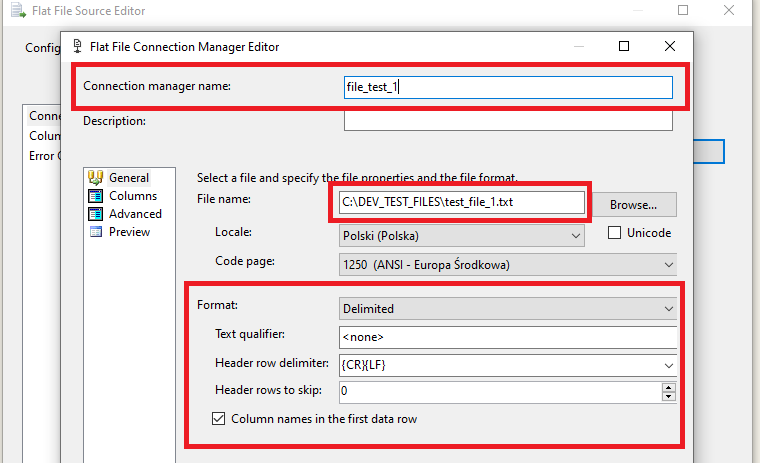
W celu powiązania pliku jako źródłowego wprowadzamy przede wszystkim nazwę połączenia oraz ścieżkę do katalogu, w którym znajduje się nasz plik. Następnie należy podać szczegóły dotyczące formatu w jakim są przygotowane dane, każdorazowo domyślnie ustawiona jest opcja „Delimited”, gdzie kolumny oddzielone są przecinkami, bądź średnikami. Kolejno możemy podać sposób w jaki są wyróżnione wartości tekstowe, jak oddzielone są wiersze oraz ile nadrzędnych wierszy ma zostać pominiętych – opcja ta jest przydatna wtedy, gdy kilka pierwszych wierszy zawiera opis, datę, nagłówek czy inną treść nie będącą elementem zbioru danych. Na koniec możemy zaznaczyć czy nazwy kolumn zawarte są w pierwszym wierszu. Po edycji pól możemy przejść do kolejnej zakładki jaką jest podgląd kolumn.
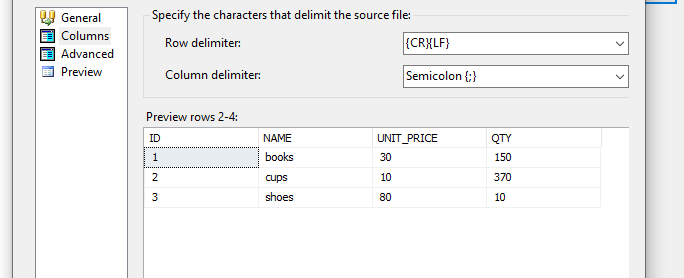
W tym miejscu możemy podejrzeć czy dobrze zostały powiązane nazwy kolumn i ich wartości oraz jak wyglądają przykładowe dane. Może wydawać się to dość prozaiczne, ale niekiedy może wystąpić błąd (np. literówka czy brak znaku) w tekście co może spowodować przesunięcie kolumn. Nie można również wykluczyć błędu po stronie konfiguracyjnej, gdzie błędnie podaliśmy średnik zamiast przecinka (lub innego znaku).
W przypadku prawidłowości formatu i wartości próbki przechodzimy dalej do zakładki „Advanced”, gdzie możemy edytować stricte każdą kolumnę osobną pod względem zawartych przez nią wartości.
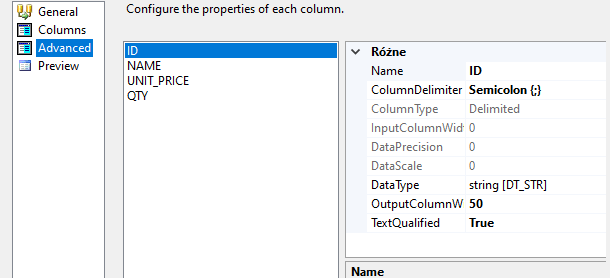
Do dostępnych zmian wlicza się zmiana formatu (np. długość znaków, precyzja) i typu danych np. ze zwykłego string na unicode string. Po naniesieniu ewentualnych poprawek zostaje nam ostateczny podgląd danych i zatwierdzenie konfiguracji. Od teraz przy naszym kafelku nie wyświetla się już czerwony „X”, co oznacza że został prawidłowo skonfigurowany.
W dalszym etapie dodamy konwersję kolumny i całość zapiszemy do innego pliku docelowego. Dorzucamy zatem dwa nowe elementy jakimi są „Data Conversion” oraz „Flat File Destination” i klikamy na nasz skonfigurowany klocek źródłowy tak, aby pojawiły się dwie strzałki służące do pokierowania dalszymi etapami w zależności czy krok ten zakończył się pomyślnie. Przeciągamy niebieską i łączymy do kolejnego kroku jakim jest konwersja danych.
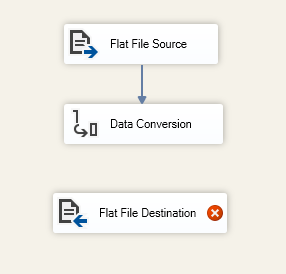
Przejdźmy zatem do konfiguracji i zamieńmy typ danych dla kolumny „UNIT_PRICE”, wskazując typ NUMERIC (precision = 18, scale = 2) wraz z podaniem skali ze względu na wyświetlenie liczb dziesiętnych. Nazwę nowej kolumny możemy podać taką samą, lecz dobrze jest dodać do niej prefix lub suffix, abyśmy mogli ją wyróżnić np. suffix *_NEW – zatem moja kolumna przyjmie nazwę UNIT_PRICE_NEW. Oczywiście przyjęty schemat jest dowolny i nazywamy ją wedle naszych własnych wytycznych i potrzeb.
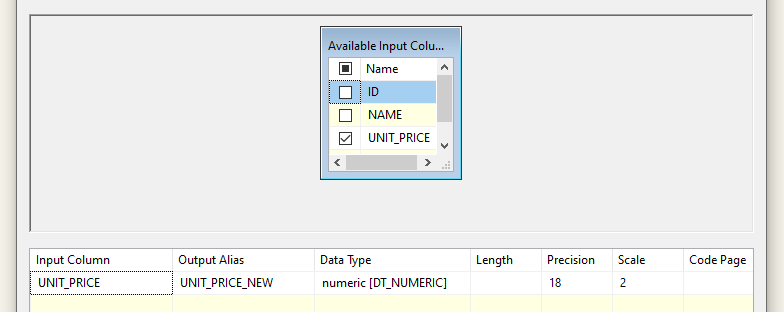
Przejdźmy do ostatniego kroku jakim jest zapisanie naszych danych do pliku docelowego. Ponownie przeciągamy i łączymy niebieską strzałką odpowiednie elementy, następnie przechodzimy do konfiguracji. Domyślnie wskazuje nam połączenie do pliku źródłowego oraz możliwość nadpisania go nowymi wartościami, ale my utworzymy nowy plik, do którego trafią nasze dane. Wybieramy zatem utworzenie nowego połączenia podczas, którego pojawi nam się okno z wyborem formatu pliku a następnie otworzy się znane nam już okno konfiguracyjne. Działamy teraz podobnie jak uprzednio, ustawiając odpowiednio każde pole zgodnie z przyjętymi warunkami. Na koniec zatwierdzamy i przechodzimy do zakładki „Mapping”, gdzie powiązujemy ze sobą odpowiednie pola – domyślnie zostaną połączone kolumny o tych samych nazwach. Pamiętajmy, że dokonaliśmy przekształcenia typu danych to działanie te utworzy nową kolumnę np. u mnie pojawią się obie kolumny, zarówno „UNIT_PRICE” oraz „UNIT_PRICE_NEW” zawierający nowy typ danych.
Teraz zostaje nam uruchomienie naszej integracji i sprawdzeniu poprawności wyników.
Otwierając plik docelowy możemy zauważyć, że obie kolumny znajdują się w nim, a nowa kolumna zawiera dodatkowo część dziesiętną, jednak separatorem jest przecinek co koliduje nam z separatorem kolumn. W tym celu musimy powrócić do naszej integracji i w ostatnim kroku zmieniamy ustawienia „locale” na amerykański, dzięki temu zostanie zastosowany wykorzystywany w tym systemie separator jakim jest kropka.

Jest to jedno z przykładowych rozwiązań jakie możemy zastosować w tym przypadku, zachęcam również do skorzystania z „Derived column” zamiast „Data Conversion” i tam zastosować alternatywne rozwiązanie powyższego przypadku.