Dzisiaj stajemy przed problemem zasilenia bazy otrzymanymi plikami, przetwarzanie każdego osobno jest jak najbardziej możliwe, jednakże co zrobimy gdy mamy do czynienia już nie z jednym a z wieloma plikami? Jedni odpowiedzą, że 10 – 20 to nie problem, drudzy że tak nie powinno być i trzeba to jakoś inaczej ugrać. Oczywiście jedni i drudzy w tym przypadku mogą mieć rację, jednak już nawet w sytuacji powtarzania jednej czynności więcej niż raz powinniśmy przemyśleć o sposobie automatyzacji. Idąc dalej to przy 100 lub tysiącach plikach sprawa się komplikuje do tego stopnia, gdzie już nie ma mowy o niczym innym niż stworzenie automatu tego oto procesu.
Czas więc odpowiedzieć sobie na pytanie „Jak to zrobić w SSIS?”. Otóż w jednym z poprzednich artykułów pobieraliśmy dane z jednego pliku i wgrywaliśmy do kolejnego. Zmiana obiektu docelowego nie stanowi dla nas dużego wyzwania, zamiast ścieżki do pliku tworzymy połączenie do bazy, wskazujemy właściwą tabelę, dopasowujemy kolumny i uruchamiamy zasilanie. Co jednak w przypadku, gdy mamy do czynienia z wieloma plikami?
Zacznijmy zatem ćwiczenia i na początku stwórzmy dowolne trzy pliki zawierające parę kolumn i wierszy, przygotowałem na potrzeby artykułu dane dotyczące zamówień w sklepie za rok 2020. Źródło zawiera po 68000 wierszy z danymi jak numer zamówienia, status oraz data złożenia zamówienia. Dla chętnych polecam lekturę o przygotowywaniu takich danych z użyciem prostego skryptu w Pythonie -> tutaj link.
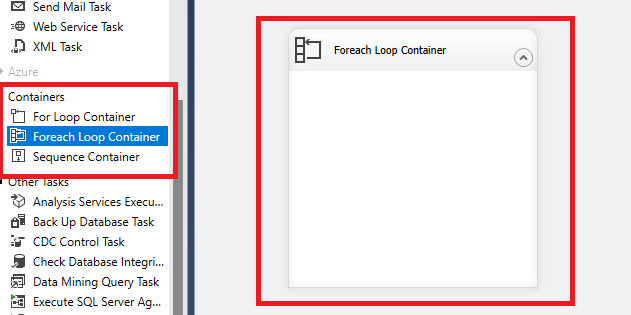
Ok, mamy źródła przejdzie zatem do stworzenia naszej nowej paczki i pierwszego elementu jakim jest kontener Foreach Loop. Pozwala on na powtarzalne zadania np. załadowanie danych z kilku plików lub wykonanie innych operacji dla obiektów z listy.
Konfigurując naszą pętlę musimy posłużyć się zmiennymi, a zatem wpierw tworzymy dwie zmienne typu tekstowego (string): jedną zawierającą ścieżkę do plików (PathToFile) oraz drugą przyjmującą nazwę plików (FileName). Dla tych, którzy jeszcze nie wiedzą jak utworzyć zmienne zapraszam pod ten artykuł -> Dodawanie zmiennej.
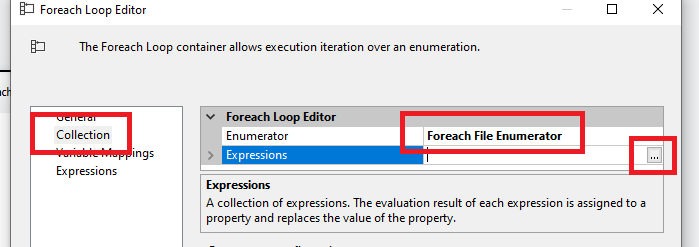
Edytujemy nasz obiekt i przechodzimy do zakładki Collection, gdzie zmieniamy rodzaj naszego iteratora na „Foreach File Enumerator”, który będzie przyjmował kolejne wartości jakimi są nasze pliki. Domyślnie może być ustawiony „Foreach Item Enumerator”, który nie posiada w swojej kolekcji obiektu Directory, gdzie wskazujemy ścieżkę źródłową poprzez zmienną PathToFile. Przechodzimy teraz do wyrażeń, gdzie dokończymy konfigurowanie kolekcji i w tym celu klikamy trzy kropki po prawej.
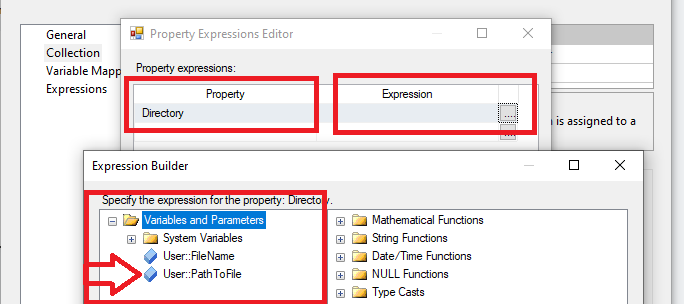
W nowym oknie będziemy możliwość wprowadzenia właściwości wyrażeń, które pozwalają nam na wszelkie operacje matematyczne, na danych tekstowych czy operatorach. Umożliwiają wprowadzanie własnych zmiennych i łączenia z innymi wartościami, gdybyśmy chcieli np. podać główny katalog a następnie zmieniać jego pod folder z różnymi kategoriami plików. My wybieramy w polu Property wartość „Directory”, w Expression przechodzimy do dalszego kroku, gdzie pojawi się nowe okno Buildera. Wybieramy tutaj z listy zmiennych naszą @PathToFile.
W efekcie nasza kolekcja powinna wyglądać następująco:

Pierwszy etap mamy już ukończony, przyszedł czas na dalsze kroki i wprowadzenie mapowania zmiennych. Posłuży to do dopełnienia naszych wartości, które już wprowadziliśmy tj. w połączeniu będziemy mieli pełną ścieżkę do pliku, która zawiera również nazwę pliku.
Konfiguracja jest na tyle prosta, że wybieramy z listy naszą kolejną zmienną @FileName.
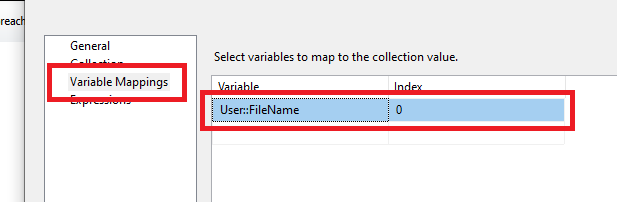
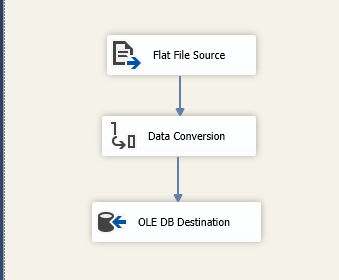
Po wszystkim wybieramy OK i zapisujemy zmiany, nasz kontener jest już gotowy. Teraz czas na przygotowanie przepływu od pliku do bazy. Stwórzmy dobrze nam znany Data Flow Task i jako pierwszy element dodajmy Flat File Source. W połączeniu wybieramy New i przechodzimy do konfiguracji, gdzie wskazujemy pierwszy plik.
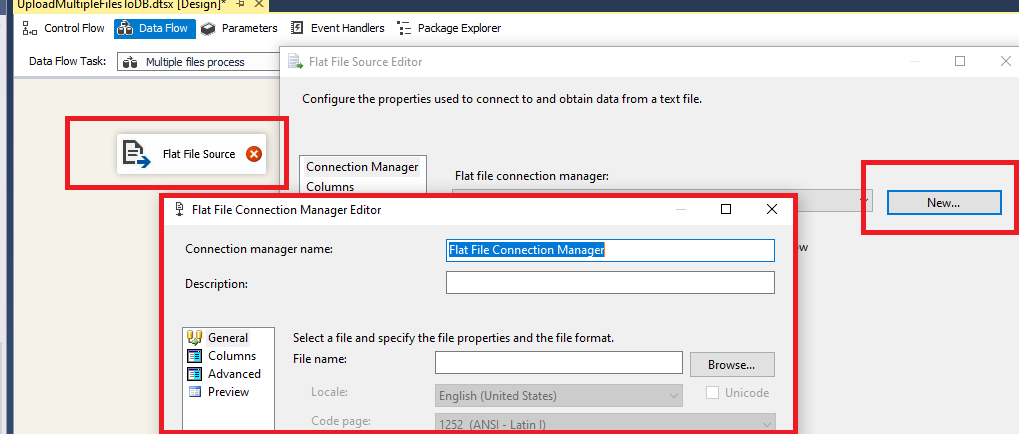
Zapisujemy wprowadzone zmiany i dodajemy kolejny element jakim jest OLEDB Destination, gdzie łączymy się do bazy i podajemy docelową tabelę w naszej bazie testowej.
Teraz jedna z najważniejszych zmian jakie dokonamy, bez której nasz przepływ nie będzie działał dla wszystkich plików, lecz co istotne TYLKO DLA JEDNEGO! Ten pierwszy plik będzie tyle razy przetwarzany ile mamy wszystkich plików. Nie obędzie się zatem bez edycji połączenia do pliku (Flat File Connection), prawym przyciskiem wybieramy owe połączenie i wybieramy Properties.
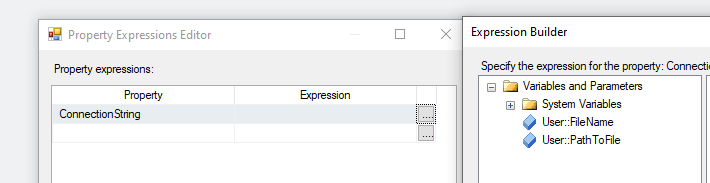
Szukamy atrybutu Expressions i przechodzimy do edycji.
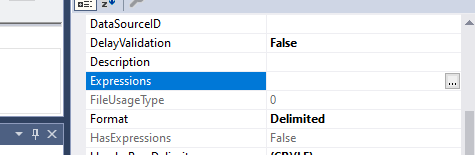
Z pośród listy wybieramy właściwość ConnectionString i powiązujemy do niej naszą zmienną @FileName.
Dzięki powyższym czynnościom nasz przepływ już będzie działał dla wszystkich plików. Kończymy nasz schemat, jeżeli będzie to konieczne to dodajemy konwersję typów danych i powiązujemy z właściwymi kolumnami.
Przyszedł moment na to co każdy programista danych wyczekuje – uruchomienie naszej paczki i ujrzenie poprawności przepływu.
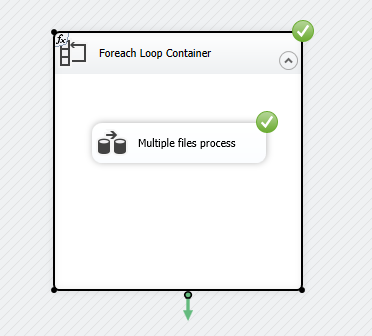
Tak też jest u nas, jeżeli nie dodalibyśmy ostatniej edycji to nasz kod również przechodziłby poprawnie z jednym wyjątkiem, jak też wspomniałem wcześniej, za każdym razem ten sam plik byłby przetwarzany. Możliwe jest to do wykrycia jedynie przeglądając logi, bądź samą tabelę docelową. W przypadku tabeli przejściowej bez wprowadzonego klucza to nawet nie byłoby problemu wprowadzić te same dane.
Ten przypadek pokazuje nam jak łatwo jest popełnić błąd, co w przypadku środowiska produkcyjnego nie zawsze jest proste do skorygowania i może skończyć się restorem.