W tym wpisie pokrótce przybliżę architekturę oraz procesy zachodzące w bazie danych ze stajni Microsoftu, pozwoli to zrozumieć podstawowe założenia, strukturę oraz działanie i rozwiać wszelkie nieścisłości z tym związane.
Powinniśmy zacząć od wskazania kilku istotnych elementów jakimi jest serwer, baza danych czy też instancja. Zacznijmy zatem od serwera, czyli fizycznej, bądź wirtualnej maszyny na której jest zainstalowana sama baza danych i to w tym miejscu są przechowywane wszelkie pliki z nią związane. Warto wspomnieć, że od zasobów tej maszyny jest zależne funkcjonowanie samej bazy, ilość procesorów, pamięci podręcznej czy wielkość dysku. W zależności od wymagań możemy przypisać dowolną ilość pamięci.
Posiadając już zainstalowany system baz danych należy wyznaczyć instancję, czyli środowisko w którym zachodzić będą wszelkie operacje oraz miejsce gdzie będą znajdować się utworzone bazy danych. Oczywiście możemy posiadać wiele instancji na jednym serwerze, a każda z nich może zawierać kilkadziesiąt baz relacyjnych. Warto wspomnieć, że każda instancja korzysta z tej samej puli zasobów, co za tym idzie jeżeli dostępną ilość pamięci RAM czy też przestrzeni dyskowej należy odpowiednio podzielić pomiędzy wszystkimi instancjami. Przejdźmy teraz do bazy danych, czyli dedykowanego miejsca gdzie będą składowane nasze dane. Wyróżnić tutaj możemy wspomniane wcześniej obiekty takie jak tabele, funkcje i procedury systemowe oraz te utworzone przez samego użytkownika. Projektując tabelę w SQL Server możemy również wskazać tak zwany schemat, który pozwala nam utrzymać porządek w postaci katalogowania według naszych potrzeb.
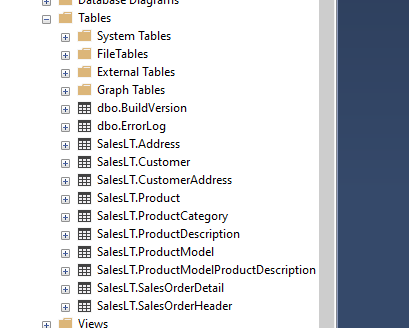
Domyślnym schematem jest „dbo”, ale możemy utworzyć kolejne np. w podziale na zastosowani tabel bądź tematyki jakiej dotyczą. Schemat sales.* zawierać będzie tabele przechowujące dane o sprzedaży, natomiast integr.* czy etl.* mogą dotyczyć tabel wykorzystywanych podczas integracji.
Struktura plików bazy danych
Struktura bazy danych opiera się na plikach, pośród których możemy wyróżnić następująco:
– plik główny bazy (ang. primary data file), posiada rozszerzenie mdf.* i to on zawiera informacje na temat bazy danych i pozostałych plików.
– plik drugorzędny/pomocniczy (ang. secondary data file), posiada rozszerzenie ndf.* i jest to plik danych, jego konfiguracja jest opcjonalna dla użytkownika
– plik dziennika transakcji (ang. transaction log), pisoada rozszerzenie ldf.* i zawiera informacje na tematy wykonywanych operacji i jest tym samym niezbędny przy wykonywaniu przywrócenia bazy z kopii zapasowych.
Można również wskazać pozostałe pliki, tutaj przykładem mogą być filestream oraz filetable.
Do prawidłowego działania bazy wymagane jest posiadanie dwóch plików, są to plik główny oraz plik logów. Podczas konfiguracji środowiska SQL podajemy ścieżki, gdzie mają być one przechowywane.
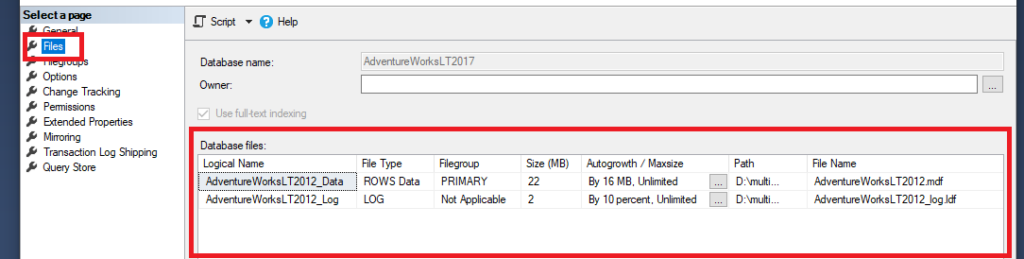
Jak widzimy na powyższym zrzucie przykładowa baza jaką jest AdventureWorks posiada podstawowe dwa pliki, główny plik MDF o nazwie AdventureWorksLT2012_Data oraz plik logu LDF o nazwie AdventureWorksLT2012_Log. Obie te nazwy są nazwami logicznymi, którymi posługujemy się podczas operacji RESTORE, warto zaznaczyć, że ich fizyczna nazwa może się różnić tak jak jest i w tym przypadku, gdzie fizyczne pliki mają nazwę zakończoną typem danego pliku. W kolumnie „Autogrowth / Maxsize” widzimy w pierwszym wierszu wartości 16 MB oraz Unlimited, oznacza to że plik główny będzie automatycznie zwiększał się co 16 MB aż do osiągnięcia drugiej wartości, która w tym przypadku jest bez limitu – jedynym ograniczeniem jest wolna przestrzeń na dysku. Alternatywnie możemy wybrać opcję rozrostu przez procenty, tak jak w przypadku drugiego pliku, gdzie mamy ustalone co 10 procent. Możemy ustawić dowolny poziom wzrostu oraz limit rozmiaru, do którego mogą urosnąć odpowiednio do naszych zasobów.